TL;DR: Combining dlt and AWS Lambda creates a secure, scalable, lightweight, and powerful instrumentation engine that Taktile uses for its low-code, high-volume data processing platform. I explain why dlt and AWS Lambda work together so well and how to get everything set up in less than one hour. If you want to jump to the code right away, you can find the accompanying GitHub repo here.
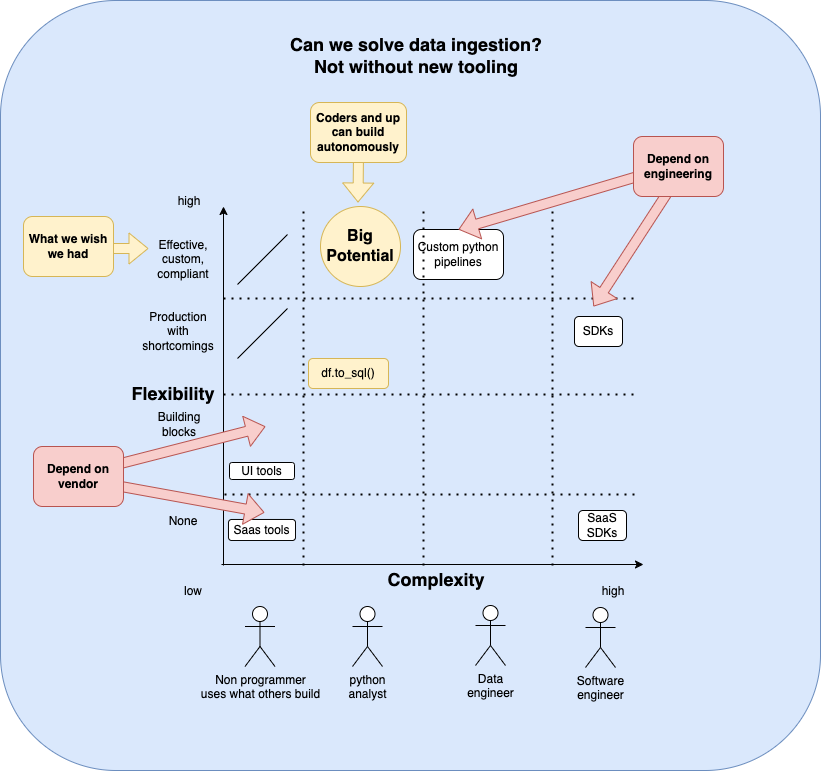
An important aspect of being a data person today is being able to navigate and choose from among many tools when setting up your company’s infrastructure. (And there are many tools out there!). While there is no one-size-fits-all when it comes to the right tooling, choosing ones that are powerful, flexible, and easily compatible with other tools empowers you to tailor your setup to your specific use case.
I am leading Data and Analytics at Taktile: a low-code platform used by global credit- and risk teams to design, build, and evaluate automated decision flows at scale. It’s the leading decision intelligence platform for the financial service industry today. To run our business effectively, we need an instrumentation mechanism that can anonymize and load millions of events and user actions each day into our Snowflake Data Warehouse. Inside the Warehouse, business users will use the data to run product analytics, build financial reports, set up automations, etc.

Choosing the right instrumentation engine is non-trivial
Setting up the infrastructure to instrument a secured, high-volume data processing platform like Taktile is complicated and there are essential considerations that need to be made:
- Data security: Each day, Taktile processes millions of high-stakes financial decisions for banks and Fintechs around the world. In such an environment, keeping sensitive data safe is crucial. Hence, Taktile only loads a subset of non-sensitive events into its warehouse and cannot rely on external vendors accessing decision data.
- Handling irregular traffic volumes: Taktile’s platform is being used for both batch and real-time decision-making, which means that traffic spikes are common and hard to anticipate. Such irregular traffic mandates an instrumentation engine that can quickly scale out and guarantee timely event ingestion into the warehouse, even under high load.
- Maintenance: a fast-growing company like Taktile needs to focus on its core product and on tools that don't create additional overhead.
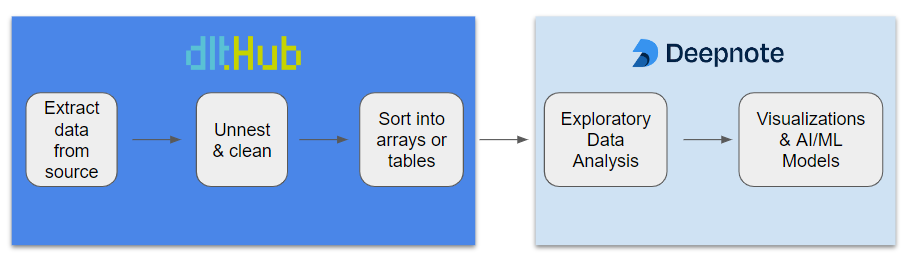
dlt and AWS Lambda as the secure, scalable, and lightweight solution
AWS Lambda is Amazon’s serverless compute service. dlt is a lightweight python ETL library that runs on any infrastructure. dlt fits neatly into the AWS Lambda paradigm, and by just adding a simple REST API and a few lines of python, it converts your Lambda function into a powerful and scalable event ingestion engine.
- Security: Lambda functions and dlt run within the perimeter of your own AWS infrastructure, hence there are no dependencies on external vendors.
- Scalability: serverless compute services like AWS Lambda are great at handling traffic volatility through built-in horizontal scaling.
- Maintenance: not only does AWS Lambda take care of provisioning and managing servers, but inserting dlt into the mix, also adds production-ready capabilities such as:
- Automatic schema detection and evolution
- Automatic normalization of unstructured data
- Easy provisioning of staging destinations

Get started with dlt on AWS Lambda using SAM (AWS Serverless Application Model)
SAM is a lightweight Infrastructure-As-Code framework provided by AWS. Using SAM, you simply declare serverless resources like Lambda functions, API Gateways, etc. in a template.yml file and deploy them to your AWS account with a lightweight CLI.
Install the SAM CLI [add link or command here]
pip install aws-sam-cliDefine your resources in a
template.ymlfileAWSTemplateFormatVersion: "2010-09-09"
Transform: AWS::Serverless-2016-10-31
Resources:
ApiGateway:
Type: AWS::Serverless::Api
Properties:
Name: DLT Api Gateway
StageName: v1
DltFunction:
Type: AWS::Serverless::Function
Properties:
PackageType: Image
Timeout: 30 # default is 3 seconds, which is usually too little
MemorySize: 512 # default is 128mb, which is too little
Events:
HelloWorldApi:
Type: Api
Properties:
RestApiId: !Ref ApiGateway
Path: /collect
Method: POST
Environment:
Variables:
DLT_PROJECT_DIR: "/tmp" # the only writeable directory on a Lambda
DLT_DATA_DIR: "/tmp" # the only writeable directory on a Lambda
DLT_PIPELINE_DIR: "/tmp" # the only writeable directory on a Lambda
Policies:
- Statement:
- Sid: AllowDLTSecretAccess
Effect: Allow
Action:
- secretsmanager:GetSecretValue
Resource: !Sub arn:aws:secretsmanager:${AWS::Region}:${AWS::AccountId}:secret:DLT_*
Metadata:
DockerTag: dlt-aws
DockerContext: .
Dockerfile: Dockerfile
Outputs:
ApiGateway:
Description: "API Gateway endpoint URL for Staging stage for Hello World function"
Value: !Sub "https://${ApiGateway}.execute-api.${AWS::Region}.amazonaws.com/v1/collect/"Build a deployment package
sam buildTest your setup locally
sam local start-api
# in a second terminal window
curl -X POST http://127.0.0.1:3000/collect -d '{"hello":"world"}'Deploy your resources to AWS
sam deploy --stack-name=<your-stack-name> --resolve-image-repos --resolve-s3 --capabilities CAPABILITY_IAM
Caveats to be aware of when setting up dlt on AWS Lambda:
No worries, all caveats described below are already being taken care of in the sample repo: https://github.com/codingcyclist/dlt-aws-lambda. I still recommend you read through them to be aware of what’s going on.
- Local files: When running a pipeline, dlt usually stores a schema and other local files under your users’ home directory. On AWS Lambda, however,
/tmpis the only directory into which files can be written. Simply tell dlt to use/tmpinstead of the home directory by setting theDLT_PROJECT_DIR,DLT_DATA_DIR,DLT_PIPELINE_DIRenvironment variables to/tmp. - Database Secrets: dlt usually recommends providing database credentials via TOML files or environment variables. However, given that AWS Lambda does not support masking files or environment variables as secrets, I recommend you read database credentials from an external secret manager like AWS Secretsmanager (ASM).
- Large dependencies: Usually, the code for a Lambda function gets uploaded as a
.ziparchive that cannot be larger than 250 MB in total (uncompressed). Given that dbt has a ~400 MB memory footprint (including Snowflake dependencies), the dlt Lambda function needs to be deployed as a Docker image, which can be up to 10 GB in size.
dlt and AWS Lambda are a great foundation for building a production-grade instrumentation engine
dlt and AWS Lambda are a very powerful setup already. At Taktile, we still decided to add a few more components to our production setup to get even better resilience, scalability, and observability:
- SQS message queue: An SQS message queue between the API gateway and the Lambda function is useful for three reasons. First, the queue serves as an additional buffer for sudden traffic spikes. Events can just fill the queue until the Lambda function picks them up and loads them into the destination. Second, an SQS queue comes with built-in batching so that the whole setup becomes even more cost-efficient. A batch of events only gets dispatched to the Lambda function when it reaches a certain size or has already been waiting in the queue for a specific period. Third, there is a dead-letter queue attached to make sure no events get dropped, even if the Lambda function fails. Failed events end up in the dead-letter queue and are sent back to the Lambda function once the root cause of the failure has been fixed.
- Slack Notifications: Slack messages help a great deal in improving observability when running dlt in production. Taktile has set up Slack notifications for both schema changes and pipeline failures to always have transparency over the health status of their pipeline.
No matter whether you want to save time, cost, or both on your instrumentation setup, I hope you give dlt and AWS Lambda a try. It’s a modern, powerful, and lightweight combination of tools that has served us exceptionally well at Taktile.





















 DeepAI Image with prompt: People stuck with tables.
DeepAI Image with prompt: People stuck with tables. The database schema as presented by a Power BI Model.
The database schema as presented by a Power BI Model.